You might be thinking, I don't need an ORM engine. I don't even know what ORM means! I know SQL backwards and forwards so there's nothing an ORM can offer me. Maybe you've had experience with other ORM engines, whether CFML-based or not, and the experience was less that ideal. Why should you consider Quick?
Quick's ORM philosophy comes down to three main points:
Give relevant names to important collections of SQL code. (, , etc.)
Make queries easy to compose at runtime to get the exact data you want in the most efficient way (, , etc.)
Get out of your way when you need or want to write barebones SQL.
Coming from Hibernate?
Quick was built out of lessons learned and persistent challenges in developing complex RDBMS applications using built-in Hibernate ORM in CFML.
Hibernate ORM error messages often obfuscate the actual cause of the error
because they are provided directly by the Java classes.
Complex CFML Hibernate ORM applications can consume significant memory and
processing resources, making them cost-prohibitive and inefficient when used
in microservices architecture.
We can do better.
Hibernate ORM is tied to the engine releases. This means that updates come
infrequently and may be costly for non-OSS engine users.
Hibernate ORM is built in Java. This limits contributions from CFML
developers who don't know Java or don't feel comfortable contributing to a
Java project.
Hibernate ORM doesn't take advantage of a lot of dynamic- and
meta-programming available in CFML. (Tools like CBORM have helped to bridge
The cookbook is a place to show examples of using Quick in practice. Each cookbook entry will include a short description of the problem to solve or use case and one or more code snippets showing the code.
The cookbook is not meant to teach you the basics of Quick or show you the method signatures. That is the purpose of the Guide and API Docs, respectively. The cookbook is meant to show you advanced and specific use cases.
Additionally, this is a great place to contribute to Quick! If you have solved a particular use case, send in a pull request and add it to the cookbook! We only ask that you take the time to simplify your example as much as you can. This usually means removing any custom naming convention for your attributes, tables, and entities.
To assist you in migrating from CBORM, Quick ships with a small compatibility shim. To use it, have your entity extend quick.models.CBORMCompatEntity. This will map common CBORM methods to their Quick counterparts as well as provide a partial CriteriaBuilder shim. The compatibility shim does not cover differences in properties or relationships.
Entity / Service Methods
list
countWhere
deleteById
deleteWhere
exists
findAllWhere
findWhere
get
getAll
new
populate
save
saveAll
newCriteria
Criteria Builder Methods
getSQL
between
eqProperty
isEQ
Retrieving Relationships
Relationships can be used in two ways.
The first is as a getter. Calling user.getPosts() will execute the relationship, cache the result, and return it.
var posts = user.getPosts();
The second is as a relationship. Calling user.posts() returns a Relationship instance to retrieve the posts that can be further constrained. A Relationship is backed by qb as well, so feel free to call any qb method to further constrain the relationship.
var newestPosts = user
.posts()
.orderBy( "publishedDate", "desc" )
.get();
You can also call the other Quick fetch methods: first, firstOrFail, find, and findOrFail are all supported. This is especially useful to constrain the entities available to a user by using the user's relationships:
Custom Getters & Setters
Sometimes you want to use a different value in your code than is stored in your database. Perhaps you want to enforce that setting a password always is hashed with BCrypt. Maybe you have a Date value object that you want wrapping each of your dates. You can accomplish this using custom getters and setters.
A custom getter or setter is simply a function in your entity.
To retrieve the attribute value fetched from the database, call retrieveAttribute passing in the name of the attribute.
To set an attribute for saving to the database, call assignAttribute passing in the name and the value.
component extends="quick.models.BaseEntity" accessors="true" {
property name="bcrypt" inject="@BCrypt";
function setPassword( value ) {
return assignAttribute( "password", bcrypt.hashPassword( value ) );
}
function getCreatedDate( value ) {
return dateFormat( retrieveAttribute( "createdDate" ), "DD MMM YYYY" );
}
}
Custom getters and setters with not be called when hydrating a model from the database. For that use case, use .
Working with Entities
isLoaded
Checks if the entity was loaded from the database.
Name
Type
Required
Default
Collections
Collections are what are returned when calling get or all on an entity. By default, it returns an array. Every entity can override its newCollection method and return a custom collection. This method accepts an array of entities and should return your custom collection.
QuickCollection is a custom collection included in Quick as an extra component. It is a specialized version of . It smooths over the various CFML engines to provide an extendible, reliable array wrapper with functional programming methods. You may be familiar with methods like map (ArrayMap), filter (ArrayFilter
// This will only find posts the user has written.
var post = user.posts().findOrFail( rc.id );
Description
No parameters
A loaded entity has a tie to the database. It has either been loaded from the database or saved to the database. An unloaded entity is one created in code but not saved to the database yet.
clone
Clones the entity and returns an exact copy of the entity.
Name
Type
Required
Default
Description
markLoaded
boolean
false
false
Mark the returned entity as loaded or not
Clones an entity and return an exact copy of the entity. This returned object is a new and separate instance from the original object.
), or
reduce
(
ArrayReduce
). These methods work in every CFML engine with
CFCollection
.
To use collections you need to install cfcollection and configure it as your as your newCollection.
Here's how you would configure an entity to return a QuickCollection.
Collections are more powerful than plain arrays. There are many methods that can make your work easier. For instance, let's say you needed to group each active user by the first letter of their username in a list.
So powerful! We think you'll love it.
load
Additionally, QuickCollection includes a load method. load lets you eager load a relationship after executing the initial query.
This is the same as if you had initially executed:
$renderData
QuickCollection includes a $renderData method that lets you return a QuickCollection directly from your handler and translates the results and the entities within to a serialized version. Check out more about it in the Serialization chapter.
Configure your defaultGrammar in config/ColdBox.cfc
Quick will auto discover your grammar by default on startup. To avoid this check, set a BaseGrammar.
defaultGrammar is a module setting for Quick. Set it in your config/ColdBox.cfc like so:
Valid options are any of the . At the time of writing valid grammar options are: MySQLGrammar@qb, PostgresGrammar@qb, SqlServerGrammar@qb and OracleGrammar@qb. You can also have qb discover your grammar on application init using AutoDiscover@qb. Please check the qb docs for additional options.
If you want to use a different datasource and/or grammar for individual entitities you can do so by attributes to your entities.
A polymorphicHasMany relationship is a one-to-many relationship. This relationship is used when an entity can belong to multiple types of entities. The classic example for this type of relationship is Posts, Videos, and Comments.
The first value passed to polymophicHasMany is a WireBox mapping to the related entity.
The second value is a prefix for the polymorphic type. A common convention where is to add able to the end of the entity name, though this is not automatically done. In our example, this prefix is commentable. This tells quick to look for a commentable_type and a commentable_id column in our Comment entity. It stores our entity's mapping as the _type and our entity's primary key value as the _id.
The inverse of polymophicHasMany is polymorphicBelongsTo.
Signature
Returns a polymorphicHasMany relationship between this entity and the entity defined by relationName.
Visualizer
Relationship Aggregates
withCount
One common type of subselect field is the count of related entites. For instance, you may want to load a Post or a list of Posts with the count of Comments on each Post. You can reuse your existing relationship definitions and add this count using the withCount method.
Adds a count of related entities as a subselect property. Relationships can be constrained at runtime by passing a struct where the key is the relationship name and the value is a function to constrain the query.
By default, you will access the returned count using the relationship name appended with Count, i.e. comments will be available under commentsCount.
You can alias the count attribute using the AS syntax as follows:
This is especially useful as you can dynamically constrain counts at runtime using the same struct syntax as eager loading with the with function.
Note that where possible it is cleaner and more readable to create a dedicated relationship instead of using dynamic constraints. In the above example, the Post entity could have pendingComments and approvedComments relationships. Dynamic constraints are more useful when applying user-provided data to the constraints, like searching.
withSum
Adds a sum of an attribute of related entities as a subselect property. Relationships can be constrained at runtime by passing a struct where the key is the relationship name and the value is a function to constrain the query.
By default, you will access the returned sum using the relationship name prepended with total, i.e. purchases.amount will be available under totalPurchases.
You can alias the count attribute using the AS syntax as follows:
This is especially useful as you can dynamically constrain counts at runtime using the same struct syntax as eager loading with the with function.
Eager Loading
The Problem
Let's imagine a scenario where you are displaying a list of posts. You fetch the posts:
And start looping through them:
When you visit the page, though, you notice it takes a while to load. You take a look at your SQL console and you've executed 26 queries for this one page! What?!?
Turns out that each time you loop through a post to display its author's username you are executing a SQL query to retreive that author. With 25 posts this becomes 25 SQL queries plus one initial query to get the posts. This is where the gets its name.
So what is the solution? Eager Loading.
Eager Loading means to load all the needed users for the posts in one query rather than separate queries and then stitch the relationships together. With Quick you can do this with one method call.
The Solution
with
You can eager load a relationship with the with method call.
with takes one parameter, the name of the relationship to load. Note that this is the name of the function, not the entity name. For example:
To eager load the User in the snippet above you would call pass author to the with method.
For this operation, only two queries will be executed:
Quick will then stitch these relationships together so when you call post.getAuthor() it will use the fetched relationship value instead of going to the database.
Nested Relationships
You can eager load nested relationships using dot notation. Each segment must be a valid relationship name.
You can eager load multiple relationships by passing an array of relation names to with or by calling with multiple times.
Constraining Eager Loaded Relationships
In most cases when you want to constrain an eager loaded relationship, the better approach is to create a new relationship.
You can eager load either option.
Occassionally that decision needs to be dynamic. For example, maybe you only want to eager load the posts created within a timeframe defined by a user. To do this, pass a struct instead of a string to the with function. The key should be the name of the relationship and the value should be a function. This function will accept the related entity as its only argument. Here is an example:
If you need to load nested relationships with constraints you can call with in your constraint callback to continue eager loading relationships.
load
Finally, you can postpone eager loading until needed by using the load method on QuickCollection. load has the same function signature as with. QuickCollection is the object returned for all Quick queries that return more than one record. Read more about it in .
hasOne
Usage
A hasOne relationship is a "one-to-one" relationship. For instance, a User entity might have an UserProfile entity attached to it.
The first value passed to hasOne is a WireBox mapping to the related entity.
Quick determines the foreign key of the relationship based on the entity name and key values. In this case, the UserProfile entity is assumed to have a userId foreign key. You can override this by passing a foreign key in as the second argument:
If your parent entity does not use id as its primary key, or you wish to join the child entity to a different column, you may pass a third argument to the hasOne method specifying your parent table's custom key.
The inverse of hasOne is . It is important to choose the right relationship for your database structure. hasOne assumes that the related model has the foreign key for the relationship.
withDefault
HasOne relationships can be configured to return a default entity if no entity is found. This is done by calling withDefault on the relationship object.
Called this way will return a new unloaded entity with no data. You can also specify any default attributes data by passing in a struct of data to withDefault.
Signature
Returns a HasOne relationship between this entity and the entity defined by relationName.
Visualizer
polymorphicBelongsTo
Usage
A polymorphicBelongsTo relationship is a many-to-one relationship. This relationship is used when an entity can belong to multiple types of entities. The classic example for this type of relationship is Posts, Videos, and Comments. For instance, a Comment may belong to a Post or a Video.
The only value passed to polymorphicBelongsTo is a prefix for the polymorphic type. A common convention where is to add able to the end of the entity name, though this is not automatically done. In our example, this prefix is commentable. This tells quick to look for a commentable_type and a commentable_id column in our Comment entity. It stores our entity's mapping as the _type and our entity's primary key value as the _id.
When retrieving a polymorphicBelongsTo relationship the _id is used to retrieve a _type from the database.
The inverse of polymorphicBelongsTo is also polymorphicHasMany. It is important to choose the right relationship for your database structure. hasOne assumes that the related model has the foreign key for the relationship.
Signature
Returns a polymorphicBelongsTo relationship between this entity and the entity defined by relationName.
Visualizer
Dynamic Datasource
Contributed by Wil de Bruin
Read about a real world usage of this pattern on Wil's blog.
Problem
Often you will configure Quick with a default datasource, but in some cases you might need a dynamic datasource. For example, your killer app is multi-tenant, each customer has it's own database but the codebase is exactly the same for each customer. In this case you have two options:
Deploy the same app over and over again for each customer, which is only feasible for a small customer count.
or create some central authentication mechanisms, and after authentication each user gets his own
userId
Solution
Actually there are multiple solutions available - you just have to pick one which suits you best. After login you know which datasource you need. Since Quick needs to know where to get the value of your datasource you need to store it somewhere. We will store it in the private request collection (prc), but other options like session storage or user-specific caching might be preferable in your use case. So let's assume we have a variable called mainDatasource in our private request collection which has the datasource name we should use. We should be able to change the default datasource in every quick object just before it sends a query to the database.
Option 1: instanceReady()
Quick fires an instanceReady event internally and as an interceptor. We will hook in to this lifecycle event by creating a base component for our entities.
In this case, I use the instanceReady() lifecycle method which fires AFTER an object is created, but before data is loaded from the database. We get the datasource from the private request collection, and only take action if it is set. If there is a value, we change the _queryoptions on the builder object. Unfortunately this is not enough, because the _queryoptions will not be read again after instanceReadyfires, so we explicitly have to set the default options on the _builder object again. Once that's done, your Quick entity is ready to query using your dynamic datasource. So every Quick entity which inherits from our custom base component will use dynamic datasources
Option 2: overriding the newQuery() method
The newQuery method reads the default _queryOptions, and prepares a query object. We create a base component again and this time override the newQuery method.
In this scenario we read the dynamic datasource value from the prc again, and modify the _queryoptions to use that datasource. Once this is ready we can call the newQuery() method of the parent object to finish setting up. Again, if your Quick entity inherits from this base, your quick object will now be using dynamic datasources.
Option 3: Intercepting qb execution
The third option might look simpler, but offers you less control. Quick uses qb to query the database, and just before it does this it announces a preQBExecute interception point. By creating and registering an interceptor, you can change your datasource just in time. The interceptor can look like this:
In this case you don't need your own base component. Be aware that this interceptor changes your datasource for ALL qb requests, no matter if you use custom base component or even if it is a regular qb query. So if qb already had some default datasource that will also be changed. We added an extra check, so this interceptor is not touching your qb query if a datasource was already explicitly defined. You can register your interceptor in the coldbox config like this
Option 2 is the most specific option you can use, and makes most sense if you see what happens in the newQuery method of quick.models.BaseEntity. Option 3 is less specific and might change your datasource in unwanted places. But if you know what you are doing it can be a very powerful way to add this dynamic datasource capability to Quick.
FAQ
What's the difference between `posts()` and `getPosts()`?
TLDR: Calling a relationship method returns a relationship component. Preceding that call with get loads and executes the relationship query.
When you define a relationship you name the function without a get in front of it. When calling a relationship with get preceding it, Quick loads the relationship and executes the query. You are returned either a single entity (or null) or an array of entities.
When you call the relationship function you get back an instance of a Quick Relationship component. This component is configured based on the entity that created it and the attributes configured in the relationship call. You can think of a relationship component as a super-charged query. In fact, you can call other Quick and qb methods on the relationship object. This is one way to restrict the results you get back.
For instance, perhaps you want to retrieve a specific Post by its id. In this case, you want the Post to be found only if it belongs to the User. You could add a constraint to a Post query on the foreign key userId like so:
Another way to write this is by leveraging existing relationships:
Let's disect this. At first glance it may look like it is just a matter of style and preference. But the power behind the relationship approach is that it encapsulates the logic to define the relationship. Remember that relationships don't have to only define foreign keys. They can define any custom query logic and give a name to it. They can even build on each other:
You see here that we have now named an important concept to our domain - a published post. Let's take this one step further and name the query logic on the Post entity itself.
Why do interception points on subclassed entities fire twice?
TLDR: Quick will call service methods first on the parent entity and then on the child entity. Both instances will fire inception point events.
When working with subclassed entities and you call a method that would change that state of the database ( such as .save() or .delete() ) quick will first retrieve an instance of the parent entity and perform the same method call on that instance before calling the method on the child class. Interception points will subsequently be fired for both method calls. To overcome this, you can explicitly check which entity was used to fire events in the code. Quick will pass the entityName in the eventData argument of the interception point which can be used to check which instance fired the event.
Can I access qb to run an SQL statement?
Quick is powered by qb and can be accessed from within Quick using either the getQB or retrieveQuery methods. For your convenience, the qb builder will have already populated the database table and column names for you in the returned qb instance.
What's the difference between retrieveAttribute( "x" ) and getX()?
getX uses onMissingMethod to call retrieveAttribute. This is so you can create your own custom getters.
When do I use a scope method and when do I use a normal method?
I keep getting a `QuickEntityNotLoaded` exception. What is the difference between a loaded entity and an unloaded entity?
How can I add a subselect field to my entity?
How can I add a computed field to my entity, like from a SQL CASE statement?
How can I always add a subselect or computed field to my queries?
belongsTo
Usage
A belongsTo relationship is a many-to-one relationship. For instance, a Post may belong to a User.
Interception Points
Quick allows you to hook in to multiple points in the entity lifecycle. If the event is on the component, you do not need to prefix it with quick. If you are listening to an interception point, include quick at the beginning.
If you create your own Interceptors, they will not fire if you define them in your Main application. quick will be loaded AFTER your interceptors, so the quick interception points will not
In this scenario you know from your user authentication info which datasource you should use for each customer. The problem: this datasource name is dynamic, while Quick knows about default datasources or fixed named datasources. So how can we make this datasource dynamic?
// User.cfc
component {
function posts() {
return hasMany( "Post" );
}
function publishedPosts() {
return hasMany( "Post" ).published(); // published is a query scope on Post
}
}
component displayname="DynamicQuickBase" extends="quick.models.BaseEntity" {
function instanceReady() {
var thisDataSource = variables._wirebox.getInstance( "coldbox:requestContext" ).getPrivateValue( "mainDatasource","" );
if ( len( thisDataSource) ){
variables._queryoptions["datasource"] = thisDataSource;
variables._builder.setDefaultOptions( variables._queryoptions );
}
}
}
component displayname="DynamicQuickBase" extends="quick.models.BaseEntity" {
/**
* Configures a new query builder and returns it.
* We modify it to get a dynamic datasource
*
* @return quick.models.QuickBuilder
*/
public any function newQuery() {
var thisDataSource = variables._wirebox.getInstance( "coldbox:requestContext" ).getPrivateValue( "customerDatasource","" );
if ( len( thisDataSource) ){
variables._queryoptions["datasource"] = thisDataSource;
}
return super.newQuery();
}
}
The column name that defines the type of the polymorphic relationship.
id
String
false
name & "_id"
The column name that defines the id of the polymorphic relationship.
localKey
String | [String]
false
related.keyNames()
The column name on the realted entity that is referred to by the foreignKey of the parent entity.
relationMethodName
String
false
The method name called on the entity to produce this relationship.
The method name called to retrieve this relationship. Uses a stack backtrace to determine by default.
DO NOT PASS A VALUE HERE UNLESS YOU KNOW WHAT YOU ARE DOING.
Name
Type
Required
Default
Description
name
String
false
relationMethodName
The name given to the polymorphic relationship.
The first value passed to
belongsTo
is a WireBox mapping to the related entity.
Quick determines the foreign key of the relationship based on the entity name and key values. In this case, the Post entity is assumed to have a userId foreign key. You can override this by passing a foreign key in as the second argument:
If your parent entity does not use id as its primary key, or you wish to join the child entity to a different column, you may pass a third argument to the belongsTo method specifying your parent table's custom key.
To update a belongsTo relationship, use the associate method. associate takes the entity to associate as the only argument.
associate does not automatically save the entity. Make sure to call save when you are ready to persist your changes to the database.
Removing
To remove a belongsTo relationship, use the dissociate method.
dissociate does not automatically save the entity. Make sure to call save when you are ready to persist your changes to the database.
Relationship Setter
You can also influence the associated entities by calling "set" & relationshipName and passing in an entity or key value.
After executing this code, the post would be updated in the database to be associated with the user with an id of 1.
withDefault
BelongsTo relationships can be configured to return a default entity if no entity is found. This is done by calling withDefault on the relationship object.
Called this way will return a new unloaded entity with no data. You can also specify any default attributes data by passing in a struct of data to withDefault.
Signature
Name
Type
Required
Default
Description
relationName
string
true
Returns a BelongsTo relationship between this entity and the entity defined by relationName.
Visualizer
hasMany
Usage
A hasMany relationship is a one-to-many relationship. For instance, a User may have multiple Posts.
The first value passed to hasMany is a WireBox mapping to the related entity.
Quick determines the foreign key of the relationship based on the entity name and key values. In this case, the Post entity is assumed to have a userId foreign key. You can override this by passing a foreign key in as the second argument:
If your parent entity does not use id as its primary key, or you wish to join the child entity to a different column, you may pass a third argument to the hasMany method specifying your parent table's custom key.
The inverse of hasMany is .
Inserting & Updating
There are two ways to add an entity to a hasMany relationship. Both mirror the for entities.
save
You can call the save method on the relationship passing in an entity to relate.
This will add the User entity's id as a foreign key in the Post and save the Post to the database.
Note: the save method is called on the posts relationship, not the getPosts collection.
saveMany
You can also add many entities in a hasMany relationship by calling saveMany. This method takes an array of key values or entities and will associate each of them with the base entity.
create
Use the create method to create and save a related entity directly through the relationship.
This example will have the same effect as the previous example.
Removing
Removing a hasMany relationship is handled in two ways: either by using the dissociate method on the side of the relationship or by deleting the side of the relationship.
Relationship Setter
You can also influence the associated entities by calling "set" & relationshipName and passing in an array of entities or key values.
After running this code, this user would only have two posts, the posts with ids 2 and 4. Any other posts would now be disassociated with this user. Likely your database will be guarding against creating these orphan records. Admittedly, this method is not as likely to be used as the others, but it does exist if it solves your use case.
Signature
Name
Type
Required
Default
Description
Returns a HasMany relationship between this entity and the entity defined by relationName.
Visualizer
hasManyDeep
Usage
A hasManyDeep relationship is either a one-to-many or a many-to-many relationship. It is used when you want to access related entities through one or more intermediate entities. For example, you may want to retrieve all the blog posts for a Team:
This would generate the following SQL:
You can generate this same relationship using a Builder syntax:
HasManyDeep relationships can also traverse pivot tables. For instance, a User may have multiple Permissions via a Role entity.
If a mapping in the through array is found as a WireBox mapping, it will be treated as a Pivot Table.
If you are traversing a polymorhpic relationship, pass an array as the key type where the first key points to the polymorphic type column and the second key points to the identifying value.
Constraining Relationships
There are two options for constraining a HasManyDeep relationship.
The first option is by using table aliases.
This produces the following SQL:
If you want to use scopes or avoid table aliases, you can use callback functions to constrain the relationship:
Signature
Subclass Entities
By default, Quick supports basic component-level inheritance of entities, meaning that a child component inherits the properties ( and ability to overload ) its parent. A common, object-oriented relational database pattern, however is to provide additional definition on parent tables ( and classes ) within child tables which contain a foreign key.
Quick supports two types of child classes: Discriminated and Subclassed child entities. In both cases, loading any child class will also deliver the data of its parent class.
Subclass Entities
Let's say, for example, that I have a
hasOneThrough
Usage
A hasOneThrough relationship is either a many-to-one or a one-to-one relationship. It is used when you want to access a related entity through one or more intermediate entities. For instance, a Team may have one latest Post
// Team.cfc
component extends="quick.models.BaseEntity" accessors="true" {
function posts() {
return hasManyDeep(
relationName = "Post",
through = [ "User" ],
foreignKeys = [
"teamId", // the key on User that refers to Team
"authorId" // the key on Post that refers to User
],
localKeys = [
"id", // the key on Team that identifies Team
"id" // the key on User that identifies User
]
);
}
}
foreignKeys
Array<String>
An array of foreign keys traversing to the relatedEntity.
The length of this array should be one more than the length of through.
The first key of this array would be the column on the first through entity that refers back to the parent (current) entity, and so forth.
localKeys
Array<String>
An array of local keys traversing to the relatedEntity.
The length of this array should be one more than the length of through.
The first key of this array would be the column on the parent (current) entity that identifies it, and so forth.
nested
boolean
false
Signals the relationship that it is currently being resolved as part of another hasManyDeep relationship. This is handled by the framework when using a hasManyThrough relationship.
relationMethodName
String
Current Method Name
The method name called to retrieve this relationship. Uses a stack backtrace to determine by default.
relationName
String | Function | QuickBuilder | IRelationship
A mapping name to the final related entity, a function that produces a QuickBuilder or Relationship instance, or a QuickBuilder or Relationship instance.
through
Array<String | Function | QuickBuilder | IRelationship>
The entities to traverse through from the parent (current) entity to get to the relatedEntity.
Each item in the array can be either a mapping name to the final related entity, a function that produces a QuickBuilder or Relationship instance, or a QuickBuilder or Relationship instance.
SELECT *
FROM `posts`
INNER JOIN `users`
ON `posts`.`authorId` = `users`.`id`
WHERE `users`.`teamId` = ? // team.getId()
// Team.cfc
component extends="quick.models.BaseEntity" accessors="true" {
function activePosts() {
return hasManyDeep(
relationName = "Post",
through = [ "User AS u" ],
foreignKeys = [
"teamId", // the key on User that refers to Team
"authorId" // the key on Post that refers to User
],
localKeys = [
"id", // the key on Team that identifies Team
"id" // the key on User that identifies User
]
).where( "u.active", 1 );
}
}
SELECT *
FROM `posts`
INNER JOIN `users` AS `u`
ON `posts`.`authorId` = `users`.`id`
WHERE `u`.`teamId` = ? // team.getId()
AND `u`.`active` = ? // 1
// Team.cfc
component extends="quick.models.BaseEntity" accessors="true" {
function activePosts() {
return hasManyDeep(
relationName = "Post",
through = [ () => newEntity( "User ).active() ],
foreignKeys = [
"teamId", // the key on User that refers to Team
"authorId" // the key on Post that refers to User
],
localKeys = [
"id", // the key on Team that identifies Team
"id" // the key on User that identifies User
]
);
}
}
entity, which is used to catalog and organize all media items loaded in to my application.
My Media entity contains all of the properties which are common to every media item uploaded in to my application. Let's say, however, that I need to have specific attributes that are available on only media for my Book entity ( e.g. whether the image is the cover photo, for example ). I can create a child class of BookMedia which extends my Media entity. When loaded, all of the properties of Media will be loaded along with the custom attributes which apply to my BookMedia object:
Note the additional component attribute joincolumn. The presence of this attribute on a child class signifies that it is a child entity of the parent and that the parent's properties should be loaded whenever the BookMedia entity is loaded. In addition, the primary key of the entity is that of the parent.
Note that a table attribute is required on a child entity if the parent entity has one. This is because ColdBox will perform a deep merge on the entire inheritance chain for metadata properties. If a parent class has a table attribute, it will show up as the child's table attribute.
Child entities can be retrieved by queries specific to their own properties:
Or properties on the parent class can be used as first-class properties within the query:
Child entities can be retrieved, individually, using the value of the joinColumn, which should be a foreign key to the parent identifier column:
Now my Book entity can use its extended media class to retrieve media items which are specific to its own purpose:
Discriminated Entities
A discriminated child class functions, basically, in the same way as a subclassed entity, with one exception: The parent entity is aware of the discriminated child due to a discriminatorValue attribute and will return a specific subclass when a retrieval is performed through the parent Entity. This pattern is also known as polymorphic association.
Quick supports two different types of discriminated entities defined by single-table inheritance (STI) or multi-table inheritance (MTI). Your database schema will determine the most appropriate inheritance pattern for your use case.
Let's take our BookMedia class again, but this time, define it as a discriminated entity.
The first step is to add the discriminatorColumn attribute to the Media entity, which is used to differentiate the subclass entities. Next, define an array of possible discriminated entities for the parent. This is so we don't have to scan all Quick components just to determine if there are any discriminated entities.
Then we set a discriminatorValue property on the child class, the value of which is stored in the parent entity table, which differentiates the different subclasses.
Then we set a discriminatorValue property on the child class, the value of which is stored in the parent entity table:
We aren’t entirely done yet. Finally, we must tell Quick whether we are using multi-table inheritance or single-table inheritance so it can map the database data to the subclass entities.
Multi-Table Inheritance (MTI)
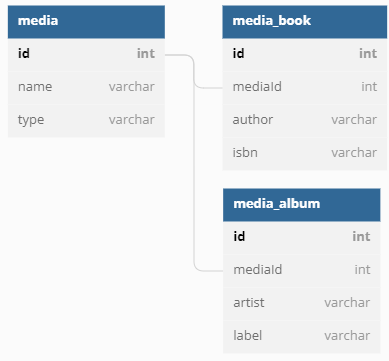
If the data for your discriminated entities is normalized across multiple tables, you should use the multi-table inheritance (MTI) method for creating discriminated entities. In the example below, The Media entity has two subclasses, MediaBook and MediaAlbum. The discriminator column for the entities is the type column in the media table and the distinct properties for each subclass come from the media_book and media_album tables.
To inform Quick that our database schema follows the MTI pattern, we must add a joinColumn and table values for each subclass.
Single Table Inheritance (STI)
If the data for your discriminated entities lives in a single table, you should use the single-table inheritance (STI) method for creating discriminated entities. In the example below, the Media entity has two subclasses, MediaBook and MediaAlbum. The discriminator column for the entities is the type column in the media table, and the distinct properties for each subclass come from a single table.
To inform Quick that our database schema follows the STI pattern, we must also add singleTableInheritance=true to the parent entity.
Retrieving Discriminated Entities
Once the parent and child entities are defined, new BookMedia entities will be saved with a type value of "book" in the media table. As such, the following query will result in only entities of BookMedia being returned:
If our Media table contains a combination of non-book and book media, then the collection returned when querying all records will contain a mix of Media entities such as BookMedia and AlbumMedia
If you want to create a brand-new entity of a specific subclass, you can do so by calling newChildEntity( discriminatorValue ) like this:
Summary
Discriminated and child class entities, allow for a more Object oriented approach to entity-specific relationships by allowing you to eliminate pivot/join tables and extend the attributes of the base class.
through a
User
.
The only value needed for hasOneThrough is an array of relationship function names to walk through to get to the related entity. The first relationship function name in the array must exist on the current entity. Each subsequent function name must exist on the related entity of the previous relationship result. For our previous example, members must be a relationship function on Team. posts must then be a relationship function on the related entity resulting from calling Team.members(). This returns a hasMany relationship where the related entity is User. So, User must have a posts relationship function. That is the end of the relationship function names array, so the related entity resulting from calling User.posts() is our final entity which is Post.
This approach can scale to as many related entities as you need. For instance, let's expand the previous example to include an Office that houses many Teams.
withDefault
HasOneThrough relationships can be configured to return a default entity if no entity is found. This is done by calling withDefault on the relationship object.
Called this way will return a new unloaded entity with no data. You can also specify any default attributes data by passing in a struct of data to withDefault.
Signature
Name
Type
Required
Default
Description
relationships
array
true
The WireBox mapping for the related entity.
foreignKey
String | [String]
false
entityName() & keyNames()
The foreign key on the parent entity.
localKey
String | [String]
false
keyNames()
The local primary key on the parent entity.
relationMethodName
String
false
The method name called on the entity to produce this relationship.
The method name called to retrieve this relationship. Uses a stack backtrace to determine by default.
DO NOT PASS A VALUE HERE UNLESS YOU KNOW WHAT YOU ARE DOING.
Serialization
getMemento
The memento pattern is an established pattern in ColdBox apps. A memento in this case is a simple representation of your entity using arrays, structs, and simple values.
For instance, the following example shows a User entity and its corresponding memento:
Quick bundles in the excellent Mementifier library to handle converting entities to mementos. This gives you excellent control over serialization using a this.memento struct on the entity and passing in arguments to the getMemento function.
this.memento
By default, Quick includes all defined attributes as includes. You can change this or add other Mementifier options by defining your own this.memento struct on your entity. Your custom this.memento struct will be merged with Quick's default, so you can only define what changes you need.
Here is the default Quick memento struct. It is inside the instanceReady() lifecycle method in this example because retrieveAttributeNames() relies on the entity being wired (though not loaded); it is not otherwise necessary to put this.memento inside instanceReady().
getMemento Arguments
You can also control the serialization of a memento at call time using Mementifier's getMemento arguments.
Custom getMemento
If this does not give you the control you need, you can further modify the memento by overriding the getMemento function on your entity. In this case, a $getMemento function will be available which is the Mementifier function.
asMemento
Sometimes when retrieving entities or executing a Quick query, you already know you want mementos back. You can skip the step of calling getMemento yourself or mapping over the array of results returned by calling asMemento before executing the query. asMemento takes the same arguments that getMemento does. It will pass those arguments on and convert your entities to mementos after executing the query. This works for all the query execution methods - find, first, get, paginate, etc.
$renderData
The $renderData method is a special method for ColdBox. When returning a model from a handler, this method will be called and the value returned will be used as the serialized response. This let's you simply return an entity from a handler for your API. By default this will call getMemento().
QuickCollection also defines a $renderData method, which will delegate the call to each entity in the collection and return the array of serialized entities.
Automatically serializing a returned collection only works when using the QuickCollection as your entity's newCollection.
asQuery
Quick can skip creating entities all together and return an array of structs from qb using the asQuery method.
asQuery also supports Eager Loading. It will add a key matching the relationship name to the returned struct.
Using asQuery is usually superior to dropping down qb using retrieveQuery since it achieves the same purpose while also including automatic aliases and eager loading.
Signature
Name
Type
Required
Default
Description
The withAliases property is recursive across eager loads. If you ask for aliases for your initial query (which is the default), all eager loaded queries will also use their respective column aliases.
Updating Existing Entities
save
Updates are handled identically to inserts when using the save method. The only difference is that instead of starting with a new entity, we start with an existing entity.
var post = getInstance( "Post" ).create( {
"title" = "My Post",
"body" = "Hello, world!"
} );
var user = getInstance( "User" ).findOrFail( 1 );
user.posts().save( post );
// OR use the keyValue
user.posts().save( post.keyValue() );
var user = getInstance( "User" ).findOrFail( 1 );
user.posts().create( {
"title" = "My Post",
"body" = "Hello, world!"
} );
var postA = getInstance( "Post" ).findOrFail( 2 );
user.setPosts( [ postA, 4 ] );
// Media (parent entity)
component
extends="quick.models.BaseEntity"
accessors="true"
table="media"
discriminatorColumn="type" // the database column that determines the subclass
{
property name="id";
property name="uploadFileName";
property name="fileLocation";
property name="fileSizeBytes";
// Array of all possible subclass entities
variables._discriminators = [
"BookMedia"
];
}
// BookMedia (subclass)
component
extends="Media"
accessors="true"
discriminatorValue="book" // column value unique to this subclass
{
property name="displayOrder";
property name="designation";
}
// BookMedia (subclass entity using MTI)
component
extends="Media"
table="media_book" // table for BookMedia data
joinColumn="mediaId" // column to join on
accessors="true"
{
// Media (parent entity)
component
extends="quick.models.BaseEntity"
accessors="true"
table="media"
discriminatorColumn="type"
singleTableInheritance="true" // Enable STI
{
var bookMedia = getInstance( "Media" ).where( "type", "book" ).get();
var allMedia = getInstance( "Media" ).all();
var newBookMedia = getInstance( "Media" ).newChildEntity( "BookMedia" );
hasOneThrough( [ "members", "posts" ] );
+----------------+---------------------------+----------------+
| Current Entity | Relationship Method Names | Related Entity |
+================+===========================+================+
| Team | members | User |
+----------------+---------------------------+----------------+
| User | posts | Post |
+----------------+---------------------------+----------------+
hasOneThrough( [ "teams", "members", "posts" ] )
+----------------+---------------------------+----------------+
| Current Entity | Relationship Method Names | Related Entity |
+================+===========================+================+
| Office | teams | Team |
+----------------+---------------------------+----------------+
| Team | members | User |
+----------------+---------------------------+----------------+
| User | posts | Post |
+----------------+---------------------------+----------------+
An array of relationship function names. The relationships are resolved from left to right. Each relationship will be resolved from the previously resolved relationship, starting with the current entity.
relationMethodName
string
false
Current Method Name
The method name called to retrieve this relationship. Uses a stack backtrace to determine by default.
withAliases
boolean
false
true
Use the aliases instead of the column names for the query.
{
"id": 1,
"title": "My First Post",
"body": "....",
"author": {
"id": 1,
"firstName": "Eric",
"lastName": "Peterson"
}
}
update
You can update multiple fields at once using the update method. This is similar to the create method for creating new entities.
Name
Type
Required
Default
Description
attributes
struct
false
{}
There is no need to call save when using the update method.
By default, if you have a key in the struct that doesn't match a property in the entity the update method will fail. If you add the optional argument ignoreNonExistentAttributes set to true, those missing keys are ignored. Now you can pass the rc scope from your submitted form directly into the update method and not worry about any other keys in the rc like event that would cause the method to fail.
updateOrCreate
Name
Type
Required
Default
Description
attributes
struct
false
{}
Updates an existing record or creates a new record with the given attributes.
updateAll
Name
Type
Required
Default
Description
attributes
struct
false
{}
Updates matching entities with the given attributes according to the configured query. This is analagous to qb's update method.
fresh
Name
Type
Required
Default
Description
No arguments
``
Retrieves a new entity from the database with the same key value as the current entity. Useful for seeing any changes made to the record in the database. This function executes a query.
refresh
Name
Type
Required
Default
Description
No arguments
``
Refreshes the attributes data for the entity with data from the database. This differs from fresh in that it operates on the current entity instead of returning a new one. This function executes a query.
hasManyThrough
Usage
A hasManyThrough relationship is either a one-to-many or a many-to-many relationship. It is used when you want to access related entities through one or more intermediate entities. The most common example for this is through a pivot table. For instance, a User may have multiple Permissions via a UserPermission entity. This allows you to store additional data on the UserPermission entity, like a createdDate .
The only value needed for hasManyThrough is an array of relationship function names to walk through to get to the related entity. The first relationship function name in the array must exist on the current entity. Each subsequent function name must exist on the related entity of the previous relationship result. For our previous example, userPermissions must be a relationship function on User. permission must then be a relationship function on the related entity resulting from calling User.userPermissions(). This returns a hasMany relationship where the related entity is UserPermission. So, UserPermission must have a permission relationship function. That is the end of the relationship function names array, so the related entity resulting from calling
Let's take a look at another example. HasManyThrough relationships can go up and down the relationship chain. Here's an example of finding a User's teammates
The inverse of hasManyThrough is either a belongsToThrough or a hasManyThrough relationship.
This approach can scale to as many related entities as you need. For instance, let's expand the previous example to include an Office that houses many Teams.
This next example can get a little gnarly - you can include other hasManyThrough relationships in a hasManyThrough relationship function names array. You can rewrite the officemates relationship like so:
As you can see, this is a very powerful relationship type that can save you many unnecessary queries to get the data you need.
Signature
belongsToMany
Usage
A belongsToMany relationship is a many-to-many relationship. For instance, a User may have multiple Permissions while a Permission can belong to multiple Users.
The first value passed to belongsToMany is a WireBox mapping to the related entity.
belongsToMany makes some assumptions about your table structure. To support a many-to-many relationship, you need a pivot table. This is, at its simplest, a table with each of the foreign keys as columns.
As you can see, Quick uses a convention of combining the entity table names in alphabetical order with an underscore (_) to create the new pivot table name. If you want to override this convention, you can do so by passing the desired table name as the second parameter or the table parameter.
Quick determines the foreign key of the relationship based on the entity name and key values. In this case, the User entity is assumed to have a userId foreign key and the Permission entity a permissionId foreign key. You can override this by passing a foreignKey in as the third argument and a relatedKey as the fourth argument:
Finally, if you are not joining on the primary keys of the current entity or the related entity, you can specify those keys using the last two parameters:
The inverse of belongsToMany is also belongsToMany. The foreignKey and relatedKey arguments are swapped on the inverse side of the relationship.
If you find yourself needing to interact with the pivot table (permissions_users) in the example above, you can create an intermediate entity, like UserPermission. You will still be able to access the end of the relationship chain using the hasManyThrough relationship type.
attach
Use the attach method to relate two belongsToMany entities together. attach can take a single id, a single entity, or an array of ids or entities (even mixed and matched) to associate.
detach
Use the detach method to remove an existing entity from a belongsToMany relationship. detatch can also take a single id, a single entity, or an array of ids or entities (even mixed and matched) to remove.
sync
Sometimes you just want the related entities to be a list you give it. For these situations, use the sync method.
Now, no matter what relationships existed before, this Post will only have three tags associated with it.
Relationship Setter
You can also influence the associated entities by calling "set" & relationshipName and passing in an entity or key value.
This code calls sync on the relationship. After executing this code, the post would be updated in the database to be associated with the tags passed in (4, 12, and 2). Any tags that were previously associated with this post would no longer be and only the tags passed in would be associated now.
Signature
Returns a BelongsToMany relationship between this entity and the entity defined by relationName.
Visualizer
var user = getInstance( "User" ).find( 1 );
user.setPassword( "newpassword" );
user.save();
var user = getInstance( "User" ).find( 1 );
user.update( {
email = "[email protected]",
password = "newpassword"
} );
var user = getInstance( "User" ).find( 1 );
user.update( rc, true );
var user = getInstance( "User" ).updateOrCreate( {
"username": "newuser"
} );
var user = getInstance( "User" ).findOrFail( rc.userID );
var sameUser = user.fresh();
var user = getInstance( "User" ).findOrFail( rc.userID );
user.refresh(); // user now has updated data from the database
A struct of key / value pairs to update on the entity.
ignoreNonExistentAttributes
boolean
false
false
If true, does not throw an exception if an attribute does not exist. Instead, it skips the non-existent attribute.
A struct of attributes to restrict the query. If no entity is found the attributes are filled on the new entity created.
newAttributes
struct
false
{}
A struct of attributes to update on the found entity or the new entity if no entity is found.
ignoreNonExistentAttributes
boolean
false
false
If true, does not throw an exception if an attribute does not exist. Instead, it skips the non-existent attribute.
The attributes to update on the matching records.
force
boolean
false
false
If true, skips read-only entity and read-only attribute checks.
UserPermission.permission()
is our final entity which is
Permission
.
relationMethodName
string
false
Current Method Name
The method name called to retrieve this relationship. Uses a stack backtrace to determine by default.
Name
Type
Required
Default
Description
relationships
array
true
An array of relationship function names. The relationships are resolved from left to right. Each relationship will be resolved from the previously resolved relationship, starting with the current entity.
hasManyThrough( [ "team", "members" ] );
+----------------+---------------------------+----------------+
| Current Entity | Relationship Method Names | Related Entity |
+================+===========================+================+
| User | team | Team |
+----------------+---------------------------+----------------+
| Team | members | User |
+----------------+---------------------------+----------------+
hasManyThrough( [ "team", "office", "teams", "members" ] );
+----------------+---------------------------+----------------+
| Current Entity | Relationship Method Names | Related Entity |
+================+===========================+================+
| User | team | Team |
+----------------+---------------------------+----------------+
| Team | office | Office |
+----------------+---------------------------+----------------+
| Office | teams | Team |
+----------------+---------------------------+----------------+
| Team | members | User |
+----------------+---------------------------+----------------+
hasManyThrough( [ "team", "office", "members" ] );
+----------------+---------------------------+----------------+
| Current Entity | Relationship Method Names | Related Entity |
+================+===========================+================+
| User | team | Team |
+----------------+---------------------------+----------------+
| Team | office | Office |
+----------------+---------------------------+----------------+
| Office | members | (below) |
+----------------+---------------------------+----------------+---+
| Office | teams | Team |
+----------------+---------------------------+----------------+
| Team | members | User |
+----------------+---------------------------+----------------+
table
String
false
Table names in alphabetical order separated by an underscore.
The table name used as the pivot table for the relationship. A pivot table is a table that stores, at a minimum, the primary key values of each side of the relationship as foreign keys.
foreignPivotKey
String | [String]
false
keyNames()
The name of the column on the pivot table that holds the value of the parentKey of the parent entity.
relatedPivotKey
String | [String]
false
The name of the column on the pivot table that holds the value of the relatedKey of the ralated entity.
parentKey
String | [String]
false
The name of the column on the parent entity that is stored in the foreignPivotKey column on table.
relatedKey
String | [String]
false
The name of the column on the related entity that is stored in the relatedPivotKey column on table.
relationMethodName
String
false
The method name called on the entity to produce this relationship.
The method name called to retrieve this relationship. Uses a stack backtrace to determine by default.
<b></b>
DO NOT PASS A VALUE HERE UNLESS YOU KNOW WHAT YOU ARE DOING.
Name
Type
Required
Default
Description
relationName
string
true
The WireBox mapping for the related entity.
Querying Relationships
When querying an entity, you may want to restrict the query based on the existence or absence of a related entity. You can do that using the following four methods:
has
Name
Checks for the existence of a relationship when executing the query.
By default, a has constraint will only return entities that have one or more of the related entity.
An optional operator and count can be added to the call.
Nested relationships can be checked by passing a dot-delimited string of relationships.
doesntHave
Checks for the absence of a relationship when executing the query.
By default, a doesntHave constraint will only return entities that have zero of the related entity.
An optional operator and count can be added to the call.
Nested relationships can be checked by passing a dot-delimited string of relationships.
whereHas
When you need to have more control over the relationship constraint, you can use whereHas. This method operates similarly to has but also accepts a callback to configure the relationship constraint.
The whereHas callback is passed a builder instance configured according to the relationship. You may call any entity or query builder methods on it as usual.
When you specify a nested relationship, the builder instance is configured for the last relationship specified.
An optional operator and count can be added to the call, as well.
whereDoesntHave
The whereDoesntHave callback is passed a builder instance configured according to the relationship. You may call any entity or query builder methods on it as usual.
When you specify a nested relationship, the builder instance is configured for the last relationship specified.
An optional operator and count can be added to the call, as well.
var post = getInstance( "Post" ).findOrFail( 1 );
var tag = getInstance( "Tag" ).create( { "name": "miscellaneous" });
// pass an id
post.tags().attach( tag.getId() );
// or pass an entity
post.tags().attach( tag );
var post = getInstance( "Post" ).findOrFail( 1 );
var tag = getInstance("Tag").firstWhere( "name", "miscellaneous" );
// pass an id
post.tags().detach( tag.getId() );
// or pass an entity
post.tags().detach( tag );
var post = getInstance( "Post" ).findOrFail( 1 );
post.tags().sync( [ 2, 3, 6 ] );
var someTag = getInstance( "Tag" ).findOrFail( 2 );
var post = getInstance( "Post" ).first();
post.setTags( [ 4, 12, someTag );
To get started with Quick, you need an entity. You start by extending quick.models.BaseEntity.
That's all that is needed to get started with Quick. There are a few defaults of Quick worth mentioning here.
You can generate Quick entities from CommandBox! Install quick-commands and use quick entity create
Ordering By Relationships
To order by a relationship field, you will use a dot-delimited syntax.
The last item in the dot-delimited string should be an attribute on the related entity.
Nested relationships are also supported. Continue to chain relationships in your dot-delimited string until arriving at the desired entity. Remember to end with the attribute to order by.
If you desire to be explicit, you can use the orderByRelated method, which is what is being called under the hood.
to get started!
Tables
We don't need to tell Quick what table name to use for our entity. By default, Quick uses the pluralized, snake_cased name of the component for the table name. That means for our User entity Quick will assume the table name is users. For an entity with multiple words like PasswordResetToken the default table would be password_reset_tokens. You can override this by specifying a table metadata attribute on the component.
Inheritance
For more information on using inheritance and child tables in your relational database model, see Subclass Entities.
Primary Key
By default, Quick assumes a primary key of id. The name of this key can be configured by setting variables._key in your component.
Key Types
Quick also assumes a key type that is auto-incrementing. If you would like a different key type, override thekeyType function and return the desired key type from that function.
Quick ships with the following key types:
AutoIncrementingKeyType
NullKeyType
ReturningKeyType
UUIDKeyType
RowIDKeyType
keyType can be any component that adheres to the keyType interface, so feel free to create your own and distribute them via ForgeBox.
Compound Keys
Quick also supports compound or composite keys as a primary key. Define your variables._key as an array of the composite keys:
Note that your chosen keyType will need to be able to handle composite keys.
Attributes
You specify what attributes are retrieved by adding properties to your component.
Now, only the id, username, and email attributes will be retrieved.
Make sure to include the primary key (id by default) as a property.
Persistent
To prevent Quick from mapping a property to a database column add the persistent="false" attribute to the property. This is needed mostly when using dependency injection.
Column
If the column name in your table is not the column name you wish to use in Quick, you can specify the column name using the column metadata attribute. The attribute will be available using the name of the attribute.
Null Values
To work around CFML's lack of null, you can use the nullValue and convertToNull attributes.
nullValue defines the value that is considered null for a attribute. By default it is an empty string. ("")
convertToNull is a flag that, when false, will not try to insert null in to the database. By default this flag is true.
Read Only
The readOnly attribute will prevent setters, updates, and inserts to a attribute when set to true.
SQL Type
In some cases you will need to specify an exact SQL type for your attribute. Any value set for the sqltype attribute will be used when inserting or updating the attribute in the database. It will also be used when you use the attribute in a where constraint.
Casts
The casts attribute allows you to use a value in your CFML code as a certain type while being a different type in the database. A common example of this is a boolean which is usually represented as a BIT in the database.
Two casters ship with Quick: BooleanCast@quick and JsonCast@quick. You can add them using those mappings to any applicable columns.
Custom Casts
The casts attribute must point to a WireBox mapping that resolves to a component that implements the quick.models.Casts.CastsAttribute interface. (The implements keyword is optional.) This component defines how to get a value from the database in to the casted value and how to set a casted value back to the database. Below is an example of the built-in BooleanCast, which comes bundled with Quick.
Casted values are lazily loaded and cached for the lifecycle of the component. Only cast values that have been loaded will have set called on them when persisting to the database.
Casts can be composed of multiple fields as well. Take this Address value object, for example:
This component is not a Quick entity. Instead it represents a combination of fields stored on our User entity:
Noticed that the casted address is neither persistent nor does it have a getter or setter created for it.
The last piece of the puzzle is our AddressCast component that handles casting the value to and from the native database values:
You can see that returning a struct of values from the set function assigns multiple attributes from a single cast.
Insert & Update
You can prevent inserting and updating a property by setting the insert or update attribute to false.
Quick uses a default datasource and default grammar, as described here. If you are using multiple datasources you can override default datasource by specifying a datasource metadata attribute on the component. If your extra datasource has a different grammar you can override your grammar as well by specifying a grammar attribute.
At the time of writing Valid grammar options are: MySQLGrammar@qb, PostgresGrammar@qb, SqlServerGrammar@qb and OracleGrammar@qb. Please check the qb docs for additional options.
Comparing Entities
You can compare entities using the isSameAs and isNotSameAs methods. Each method takes another entity and returns true if the two objects represent the same entity.
Type
Required
Default
Description
relationshipName
String | [String]
true
A dot-delimited string of relationship names or an array of relationship names to traverse to get to the related entity to order by.
columnName
string
true
The column name in the final relationship to order by.
direction
string
false
"asc"
The direction to sort, asc or desc.
You might prefer the explicitness of this method, but it cannot handle normal orders like orderBy. Use whichever method you prefer.
interface displayname="KeyType" {
/**
* Called to handle any tasks before inserting into the database.
* Recieves the entity as the only argument.
*/
public void function preInsert( required entity );
/**
* Called to handle any tasks after inserting into the database.
* Recieves the entity and the queryExecute result as arguments.
*/
public void function postInsert( required entity, required struct result );
}
// BooleanCast.cfc
component implements="CastsAttribute" {
/**
* Casts the given value from the database to the target cast type.
*
* @entity The entity with the attribute being casted.
* @key The attribute alias name.
* @value The value of the attribute.
*
* @return The casted attribute.
*/
public any function get(
required any entity,
required string key,
any value
) {
return isNull( arguments.value ) ? false : booleanFormat( arguments.value );
}
/**
* Returns the value to assign to the key before saving to the database.
*
* @entity The entity with the attribute being casted.
* @key The attribute alias name.
* @value The value of the attribute.
*
* @return The value to save to the database. A struct of values
* can be returned if the cast value affects multiple attributes.
*/
public any function set(
required any entity,
required string key,
any value
) {
return arguments.value ? 1 : 0;
}
}
// Address.cfc
component accessors="true" {
property name="streetOne";
property name="streetTwo";
property name="city";
property name="state";
property name="zip";
function fullStreet() {
var street = [ getStreetOne(), getStreetTwo() ];
return street.filter( function( part ) {
return !isNull( part ) && part != "";
} ).toList( chr( 10 ) );
}
function formatted() {
return fullStreet() & chr( 10 ) & "#getCity()#, #getState()# #getZip()#";
}
}
component implements="quick.models.Casts.CastsAttribute" {
property name="wirebox" inject="wirebox";
/**
* Casts the given value from the database to the target cast type.
*
* @entity The entity with the attribute being casted.
* @key The attribute alias name.
* @value The value of the attribute.
* @attributes The struct of attributes for the entity.
*
* @return The casted attribute.
*/
public any function get(
required any entity,
required string key,
any value
) {
return wirebox.getInstance( dsl = "Address" )
.setStreetOne( entity.retrieveAttribute( "streetOne" ) )
.setStreetTwo( entity.retrieveAttribute( "streetTwo" ) )
.setCity( entity.retrieveAttribute( "city" ) )
.setState( entity.retrieveAttribute( "state" ) )
.setZip( entity.retrieveAttribute( "zip" ) );
}
/**
* Returns the value to assign to the key before saving to the database.
*
* @entity The entity with the attribute being casted.
* @key The attribute alias name.
* @value The value of the attribute.
* @attributes The struct of attributes for the entity.
*
* @return The value to save to the database. A struct of values
* can be returned if the cast value affects multiple attributes.
*/
public any function set(
required any entity,
required string key,
any value
) {
return {
"streetOne": arguments.value.getStreetOne(),
"streetTwo": arguments.value.getStreetTwo(),
"city": arguments.value.getCity(),
"state": arguments.value.getState(),
"zip": arguments.value.getZip()
};
}
}
Returns the SQL that would be executed for the current query.
The bindings for the query are represented by question marks (?) just as when using queryExecute. qb can replace each question mark with the corresponding cfqueryparam-compatible struct by passing showBindings = true to the method.
tap
Executes a callback with the current entity passed to it. The return value from tap is ignored and the current entity is returned.
While not strictly a debugging method, tap makes it easy to see the changes to an entity after each call without introducing temporary variables.
dump
A shortcut for the most common use case of tap. This forwards on the SQL for the current query to writeDump. You can pass along any writeDump argument to dump and it will be forward on. Additionally, the showBindings argument will be forwarded on to the toSQL call.
Debugging All Queries
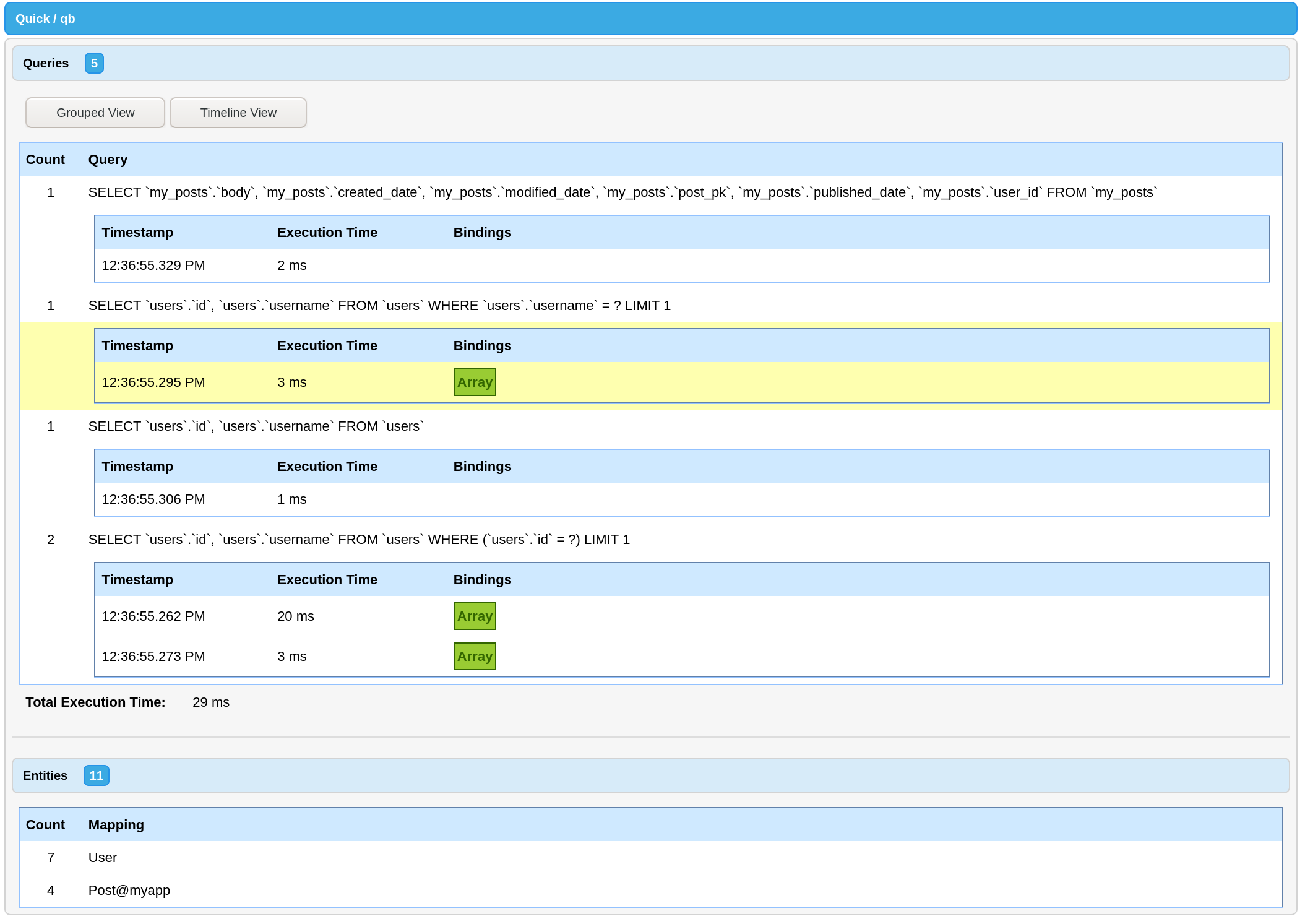
cbDebugger
Starting in 2.0.0 you can view all your Quick and qb queries for a request. This is the same output as using qb standalone. This is enabled by default if you have qb installed. Make sure your debug output is configured correctly and scroll to the bottom of the page to find the debug output.
Additionally, with Quick installed you will see number of loaded entities for the request. This can help identify places that are missing pagination or relationships that could be tuned or converted to a subselect.
LogBox Appender
Quick is set to log all queries to a debug log out of the box via qb. To enable this behavior, configure LogBox to allow debug logging from qb's grammar classes.
qb can be quite chatty when executing many database queries. Make sure that this logging is only enabled for your development environments using .
Interception Points
ColdBox Interception Points can also be used for logging, though you may find it easier to use LogBox. See the documentation for or Quick's for more information.
Name
Type
Required
Default
Description
showBindings
boolean | string
false
false
If true, the bindings for the query will be substituted back in where the question marks (?) appear as cfqueryparam structs. If inline, the binding value will be substituted back creating a query that can be copy and pasted to run in a SQL client.
A function to execute with an instance of the current entity.
If true, the bindings for the query will be substituted back in where the question marks (?) appear as cfqueryparam structs. If inline, the binding value will be substituted back creating a query that can be copy and pasted to run in a SQL client.
Introduction
Quick logo
A CFML ORM Engine
Why?
Quick was built out of lessons learned and persistent challenges in developing complex RDBMS applications using built-in Hibernate ORM in CFML.
Hibernate ORM error messages often obfuscate the actual cause of the error
because they are provided directly by the Java classes.
Complex CFML Hibernate ORM applications can consume significant memory and
processing resources, making them cost-prohibitive and inefficient when used
in microservices architecture.
We can do better.
What?
Quick is an ORM (Object Relational Mapper) written in CFML for CFML. It provides an implementation for working with your database. With it you can map database tables to components, create relationships between components, query and manipulate data, and persist all your changes to your database.
Prerequisites
You need the following configured before using Quick:
Configure a default datasource in your CFML engine
ColdBox 4.3+
Add a mapping for quick in your Application.cfc
See for more details.
Supported Databases
Quick supports all databases supported by .
Example
Here's a "quick" example to whet your appetite.
We'll show the database structure using a . This isn't required to use quick, but it is highly recommended.
Now that you've seen an example, with Quick!
Prior Art, Acknowledgements, and Thanks
Quick is backed by . Without qb, there is no Quick.
Quick is inspired heavily by . Thank you Taylor Otwell and the Laravel community for a great library.
Development of Quick is sponsored by Ortus Solutions. Thank you Ortus Solutions for investing in the future of CFML.
Discussion & Help
The Box products community for further discussion and help can be found here:
New Quick entities can be created and persisted to the database by creating a new entity instance, setting the attributes on the entity, and then calling the save method.
When we call save, the record is persisted from the database and the primary key is set to the auto-generated value (if any).
We can shortcut the setters above using a fill method.
fill
Finds the first matching record or creates a new entity.
Sets attributes data from a struct of key / value pairs. This method does the following, in order:
Guard against read-only attributes.
Attempt to call a relationship setter.
Calls custom attribute setters for attributes that exist.
populate
Populate is simply an alias for fill. Use whichever one suits you best.
create
Creates a new entity with the given attributes and then saves the entity.
There is no need to call save when using the create method.
firstOrNew
Finds the first matching record or returns an unloaded new entity.
firstOrCreate
Finds the first matching record or creates a new entity.
findOrNew
Returns the entity with the id value as the primary key. If no record is found, it returns a new unloaded entity.
findOrCreate
Returns the entity with the id value as the primary key. If no record is found, it returns a newly created entity.
updateOrCreate
Updates an existing record or creates a new record with the given attributes.
Hydration Methods
Hydration is a term to describe filling an entity with a struct of data and then marking it as loaded, without doing any database queries. For example, this might be useful when hydrating a user from session data instead of doing a query every request.
hydrate
Hyrdates an entity from a struct of data. Hydrating an entity fills the entity and then marks it as loaded.
If the entity's keys are not included in the struct of data, a MissingHydrationKey is thrown.
hydrateAll
Hydrates a new collection of entities from an array of structs.
// User
component extends="quick.models.BaseEntity" {
// the name of the table is the pluralized version of the model
// all fields in a table are mapped by default
// both of these points can be configured on a per-entity basis
}
// handlers/Users.cfc
component {
// /users/:id
function show( event, rc, prc ) {
// this finds the User with an id of 1 and retrieves it
prc.user = getInstance( "User" ).findOrFail( rc.id );
event.setView( "users/show" );
}
}
Handle skipping constraints when a relationship is defined with other relationships
8.0.1
Make the withoutRelationshipConstraints check more resilient by checking against a set of relationship method names.
8.0.0
BREAKING CHANGE
The withoutRelationshipConstraints method now requires the relationship method name as the first parameter.
This is used to ensure only the desired relationship has its constraints skipped. This is especially important in asynchronous contexts.
7.4.4
Fix for thread safety when loading multiple relationships off of a single entity
7.4.3
Fix qualifying column issue when using HasManyDeep relationships.
7.4.2
Remove duplicate join from addCompareConstraints when using HasManyDeep relationships.
7.4.1
Upgrade to latest str dependency
7.4.0
HasManyDeep
Introduced a new alternative relationship to the old hasManyThrough — hasManyDeep. It produces more readable, parsable SQL and is the basis for the new version of hasManyThrough.
HasManyDeepBuilder
If you prefer the hasManyDeep syntax over the hasManyThrough syntax, you might enjoy the HasManyDeepBuilder, a builder object to create the hasManyDeep relationship. It is generally more readable, especially when using additional constraints on related or through entities, at the cost of verbosity.
Revamped HasManyThrough relationships
All hasManyThrough relationships are now hasManyDeep relationships under the hood. No code changes should be necessary for you to enjoy more readable SQL, less bugs, and greater performance. 🏎️
7.3.2
Use the interceptor approach instead of wirebox:targetId to support CommandBox 5.
7.3.1
Fix where discriminated entities could use the wrong qualified column name in the join with the parent entity.
7.3.0
New Features
Return optional QuickBuilder instances for withCount and withSum to allow for further chaining.
Bug Fixes
Fix clearAttribute when not setting to null.
Fix using a QueryBuilder instance to define a subselect.
Additional Test Cases
Add test case for checking null attributes on newly created entities.
Add test case for deleteAll off of a hasMany relationship.
Add test case for belongsToMany
7.2.0
Allow setting for the underlying qb instance backing Quick.
7.1.1
Pin to version 3.
7.1.0
Add a method, similar to for quickly adding a subselect based on the sum of a relationship's attribute.
7.0.1
Correctly handle null values with casted attributes.
7.0.0
QuickBuilder now has its own clone method that behaves as you would expect. Previously, it only cloned the enclosed QueryBuilder which was not that useful.
Making this fix required the newQuery method of QuickBuilder to return an instance of QuickBuilder instead of QueryBuilder as it previously was. If you need a new QueryBuilder instance from a QuickBuilder, use the newQuickQB method.
6.2.1
Allow a QuickBuilder to be used wherever a QueryBuilder can be used.
6.2.0
Add the ability to .
6.1.0
Introducing the asQuery method
This method is similar to asMemento. You use it when the return format you want is an array of structs. asQuery will skip creating entities at all, instead returning the values straight from qb. This can result in a large performance boost depending on the number of records being returned. Additionally, asQuery supports returning the columns using the alias names and returning eager loaded entities.
Read more in the docs.
6.0.0
Add compatibility with ColdBox 7.
Fixed a bug where once a virtual attribute was added to an entity it was added to all future entities of that same type.
Dropped support for ColdBox 5.
5.3.3
Use correct nesting for where statements
5.3.2
Fixed retrieving null values from fields and relationships
5.3.1
Special handling for Lucee generated keys
Workaround for adobe@2021 not supporting null values in param statements
Upgrade to latest cfmigrations (v4.0.0)
5.3.0
Add a way to not fire events inside a callback using withoutFiringEvents.
5.2.11
Upgrade to qb 9
5.2.10
HasOneOrManyThrough: Fix too many joins for has and whereHas
5.2.9
HasOneOrManyThrough: Fixed applying of through constraints
BaseEntity: Use wirebox to get the util to work in CommandBox
5.2.8
Fix bad link to Getting Started guide
5.2.7
Use existing builder when adding subselects
5.2.6
Update to latest mementifier (v3.0.0)
5.2.5
CommandBox compatibility
5.2.4
Force generated key to be an integer.
5.2.3
CommandBox-friendly injections using the box namespace.
5.2.2
Fixed regression where eager loading inside a relationship was broken.
5.2.1
Fixed accessing QuickBuilder from entities and relationships.
5.2.0
Add include and exclude arguments to method.
5.1.3
Always return numeric value for .
5.1.2
Add the builder to the preInsert method for .
5.1.1
Set the table when creating new queries.
5.1.0
Added support for with discriminated subclass entities.
5.0.0
In 5.0.0, we stepped up the performance of Quick in a major way. Entity creation is now over twice as fast as before.
Performance Improvements
Average duration to create one entity:
Engine
4.2.0
5.0.0
While the times may seem small, this is compounded for each entity you create. So, if you are retrieving 1000 entities, multiply each of these numbers by 1000 and you'll start to see why this matters.
This did introduce one breaking change from v4. See the for more information.
New Features
Added a new that will correctly set your primary key if your database only returns ROWID in the queryExecute response.
Bug Fixes
Fixed a null check in isNullValue.
Fixed nulls coming back as strings in JsonCast.
4.2.0
Add a pagination method for quicker performance when total records or total pages are not needed or too slow.
4.1.6
Configure columns are no longer cleared when setting up a BelongsToMany relationship.
4.1.5
Provide initialThroughConstraints for hasOne relationships (used in *Through relationships).
4.1.4
Ignore orders when retrieving a relationship count.
4.1.1, 4.1.2
Preserve casted value after saving an entity.
4.1.0
Allow for including
Look up returning values by column name not by alias in the ReturningKeyType.
4.0.2
Skip eager loading database call when no keys are found.
Only apply CONCAT when needed in *Through relationships.
4.0.1
Use WHERE EXISTS over DISTINCT when fetching relationships. DISTINCT restricts some of the queries that can be run.
4.0.0
📹
BREAKING CHANGES
, , and callbacks now automatically group where clauses when an OR combinator is detected.
Other Changes
Dynamically add to a parent entity without loading all of the relationship.
Give a helpful error message when trying to set relationship values before saving an entity, where applicable.
Multiple bug fixes related to and when using belongsToThrough
3.1.7
Correct jQuery link in test runner.
3.1.6
Allow expressions in basic where clauses.
Fix delete naming collision.
3.1.5
Add an alias to with to QuickBuilder.
3.1.4
Fix a stack overflow on nested relationship checks.
3.1.3
Configured tables (.from) are now used for qualifying columns.
3.1.2
Remove unnecessary nesting in compare queries.
3.1.1
Fix when using "OR" combinators.
3.1.0
Add support for JSON using a new JsonCast@quick component.
3.0.4
Compatibility updates for ColdBox 6
3.0.3
Optimize caching
3.0.2
Apply during .
3.0.1
Account for null values in .
Swap structAppend order for a Lucee bug in mementifier integration.
3.0.0
BREAKING CHANGES
Please see the for more information on these changes.
Drop support for Lucee 4.5 and Adobe ColdFusion 11.
Virtual Inheritance (using a quick annotation instead of extending quick.models.BaseEntity) has been removed. It was hardly used, and removing it allows us to simplify some of the code paths.
Other Changes
for memento transformations.
Use to automatically convert queries to mementos.
Automatically-generated .
2.5.0
Define per entity.
2.4.0
Apply custom setters when hydrating from the database. (Reverted in 2.5.3 for unintended consequences with things like password hashing.)
This allows you to use scopes to perform query functions and return values. (If you do not want to return a custom value, return the QueryBuilder instance or nothing.)
2.3.0
2.2.0
(first and find methods)
2.1.0
Mapping foreign keys for relationships is now optional
withCount
.
Add test case for firstOrNew with aliases and columns.
lucee@5
3.94 ms
0.88 ms
,
hasOneThrough
, or
hasManyThrough
.
accessors="true" is now required on every entity. This is similar to above where requiring it allows us to simplify the codebase immensely. A helpful error message will be thrown if accessors="true" is not present on your entity.
The defaultGrammar mapping needs to be the full WireBox mapping, including the @qb, if needed.
For instance, MSSQLGrammar would become MSSQLGrammar@qb.
This will allow for other grammars to be more easily contributed via third party modules.
HasManyThrough relationships now only accept a relationships parameter of relationship methods to walk to get to the intended entity.
Some method and parameter names have been changed to support composite keys. The majority of changes will only affect you if you have extended base Quick components. The full list can be found in the Upgrade Guide.
Query scopes are a way to encapsulate query constraints in your entities while giving them readable names .
belongsToThrough
Usage
A belongsToThrough relationship is the one side of a many-to-one relationship with an intermediate entity. It is used when you want to access a related, owning entity through one or more intermediate entities. For instance, a Post may belong to a Team
A Practical Example
For instance, let's say that you need to write a report for subscribers to your site. Maybe you track subscribers in a users table with a boolean flag in a subscribed column. Additionally, you want to see the oldest subscribers first. You keep track of when a user subscribed in a subscribedDate column. Your query might look as follows:
Now nothing is wrong with this query. It retrieves the data correctly and you continue on with your day.
Later, you need to retrieve a list of subscribed users for a different part of the site. So, you write a query like this:
We've duplicated the logic for how to retrieve active users now. If the database representation changed, we'd have to change it in multiple places. For instance, what if instead of keeping track of a boolean flag in the database, we just checked that the subscribedDate column wasn't null?
Now we see the problem. Let's look at the solution.
The key here is that we are trying to retrieve subscribed users. Let's add a scope to our User entity for subscribed:
Now, we can use this scope in our query:
We can use this on our first example as well, for our report.
We've successfully encapsulated our concept of a subscribed user!
We can add as many scopes as we'd like. Let's add one for longestSubscribers.
Now our query is as follows:
Best of all, we can reuse those scopes anywhere we see fit without duplicating logic.
Usage
All query scopes are methods on an entity that begin with the scope keyword. You call these functions without the scope keyword (as shown above).
Each scope is passed the query, a reference to the current QuickBuilder instance, as the first argument. Any other arguments passed to the scope will be passed in order after that.
Scopes that Return Values
All of the examples so far either returned the QuickBuilder object or nothing. Doing so lets you continue to chain methods on your Quick entity. If you instead return a value, Quick will pass on that value to your code. This lets you use scopes as shortcut methods that work on a query.
For example, maybe you have a domain method to reset passwords for a group of users, and you want the count of users updated returned.
Global Scopes
Occasionally, you want to apply a scope to each retrieval of an entity. An example of this is an Admin entity which is just a User entity with a type of admin. Global Scopes can be registered in the applyGlobalScopes method on an entity. Inside this entity you can call any number of scopes:
These scopes will be applied to the query without needing to call the scope again.
To temporarily disable global scopes that have been applied to an entity, you have the option to disable them individually or all at once by utilizing the withoutGlobalScope method.
Subselects
Subselects are a useful way to grab data from related tables without having to execute the full relationship. Sometimes you just want a small piece of information like the lastLoginDate of a user, not the entire Login relationship. Subselects are perfect for this use case. You can even use subselects to provide the correct key for dynamic subselect relationships. We'll show how both work here.
Quick handles subselect properties (or computed or formula properties) through query scopes. This allows you to dynamically include a subselect. If you would like to always include a subselect, add it to your entity's list of global scopes.
Here's an example of grabbing the lastLoginDate for a User:
We'd add this subselect by calling our scope:
We can even constrain our User entity based on the value of the subselect, so long as we've called the scope adding the subselect first (or made it a global scope).
Or add a new scope to User based on the subselect:
In this example, we are using the addSubselect helper method. Here is that function signature:
Argument
Type
Required
Default
Description
name
string
true
The name for the subselect. This will be available as an attribute.
You might be wondering why not use the logins relationship? Or even logins().latest().limit( 1 ).get()? Because that executes a second query. Using a subselect we get all the information we need in one query, no matter how many entities we are pulling back.
Using Relationships in Subselects
In most cases the values you want as subselects are values from your entity's relationships. In these cases, you can use a shortcut to define your subselect in terms of your entity's relationships represented as a dot-delimited string.
Let's re-write the above subselect for lastLoginDate for a User using the existing relationship:
Much simpler! In addition to be much simpler this code is also more dynamic and reusable. We have a relationship defined for logins if we need to fetch them. If we change how the logins relationship is structured, we only have one place we need to change.
With the query cleaned up using existing relationships, you might find yourself adding subselects directly in your handlers instead of behind scopes. This is fine in most cases. Keep an eye on how many places you use the subselect in case you need to re-evaluate and move it behind a scope.
Dynamic Subselect Relationships
Subselects can be used in conjunction with relationships to provide a dynamic, constrained relationship. In this example we will pull the latest post for a user.
This can be executed as follows:
As you can see, we are loading the id of the latest post in a subquery and then using that value to eager load the latestPost relationship. This sequence will only execute two queries, no matter how many records are loaded.
Virtual Attributes
Virtual attributes are attributes that are not present on the table backing the Quick entity. A Subselect is an example of a virtual attribute. Other examples could include calculated counts or CASE statement results.
By default, if you add a virtual column to a Quick query, you won't see anything in the entity. This is because Quick needs to have an attribute defined to map the result to. You can create a virtual attribute in these cases.
This step is unnecessary when using the addSubselect helper method.
Here's an example including the result of a CASE statement as a field:
With this code, we could now access the publishedStatus just like any other attribute. It will not be updated, inserted, or saved though, as it is just a virtual column.
The appendVirtualAttribute method adds the given name as an attribute available in the entity.
appendVirtualAttribute
Argument
Type
Required
Default
Description
name
string
true
The attribute name to create.
Creates a virtual attribute for the given name.
It is likely that Quick will introduce more helper methods in the future making these calls simpler.
via a
User
.
The only value needed for belongsToThrough is an array of relationship function names to walk through to get to the related entity. The first relationship function name in the array must exist on the current entity. Each subsequent function name must exist on the related entity of the previous relationship result. For our previous example, author must be a relationship function on Post. team must then be a relationship function on the related entity resulting from calling Post.author(). This returns a belongsTo relationship where the related entity is User. So, User must have a team relationship function. That is the end of the relationship function names array, so the related entity resulting from calling User.team() is our final entity which is Team.
This approach can scale to as many related entities as you need. For instance, let's expand the previous example to include an Office that houses many Teams.
withDefault
HasOneThrough relationships can be configured to return a default entity if no entity is found. This is done by calling withDefault on the relationship object.
Called this way will return a new unloaded entity with no data. You can also specify any default attributes data by passing in a struct of data to withDefault.
var users = getInstance( "User" ).withLatestPost().all();
for ( var user in users ) {
user.getLatestPost().getTitle(); // My awesome post, etc.
}
// Post.cfc
component extends="quick.models.BaseEntity" accessors="true" {
function scopeAddType( qb ) {
qb.selectRaw( "
CASE
WHEN publishedDate IS NULL THEN 'unpublished'
ELSE 'published'
END AS publishedStatus
" );
appendVirtualAttribute( "publishedStatus" );
}
}
belongsToThrough( [ "author", "team" ] );
+----------------+---------------------------+----------------+
| Current Entity | Relationship Method Names | Related Entity |
+================+===========================+================+
| Post | author | User |
+----------------+---------------------------+----------------+
| User | team | Team |
+----------------+---------------------------+----------------+
Either a dot-delimited string representing a relationship chain ending with an attribute name, a QueryBuilder object, or a closure that configures a QueryBuilder object can be provided. If a closure is provided it will be passed a query object as its only parameter. The resulting query object will be used to computed the subselect.
An array of relationship function names. The relationships are resolved from left to right. Each relationship will be resolved from the previously resolved relationship, starting with the current entity.
relationMethodName
string
false
Current Method Name
The method name called to retrieve this relationship. Uses a stack backtrace to determine by default.
Upgrade Guide
8.0.0
The withoutRelationshipConstraints method now requires the relationship method name as the first parameter.
This is used to ensure only the desired relationship has its constraints skipped. This is especially important in asynchronous contexts.
7.0.0
QuickBuilder.newQuery() now returns QuickBuilder instances
Calling newQuery on a QuickBuilder now returns a new QuickBuilder instance instead of a new QueryBuilder instance. If you needed a QueryBuilder instance, use the newQuickQB method instead.
6.0.0
Dropped support for ColdBox 5
It's very likely that Quick v6 will still work on ColdBox 5, but it is no longer an officially supported platform.
5.1.0
KeyType now accepts the builder as a second argument to `preInsert`
This is only a breaking change if you have built your own key types. This is being released as a bug fix since the ReturningKeyType has not worked correctly since 5.0.0
5.0.0
Dropped support for Adobe ColdFusion 2016
Please upgrade to a supported engine.
`addSubselect` calls must be accessed on the QuickBuilder
This means for scopes, you must call addSubselect off of the passed in builder object.
`applyGlobalScopes` functions now receive a Builder instance that should be used to call scopes
Instead of this:
the scopes should be called on the passed in Builder instance:
4.0.0
Scopes, whereHas, and whereDoesntHave are now automatically grouped when using an OR combinator
This isn't a breaking change that will affect most people. In fact, it will most likely improve your code.
Previously, when using , , or , you were fully responsible for the wrapping of your where statements. For example, the following query:
with the following scopes defined:
would generate the following SQL:
The problem with this statement is that the OR can short circuit the active check.
The fix is to wrap the LIKE statements in parenthesis. This is done in qb using a function callback to where. Adding this nesting inside our scope will fix this problem.
But this was easy to miss this. This is because you are in a completely different file than the built query. It also breaks the mental model of a scope as an encapsulated piece of SQL code.
In Quick 4.0.0, scopes, whereHas, and whereDoesntHave will automatically group added where clauses when needed. That means our original example now produces the SQL we probably expected.
Grouping is not needed if there is no OR combinator. In these cases no grouping is added.
If you had already wrapped your expression in a group inside the scope, whereHas, or whereDoesntHave call, nothing changes. Your code works as before. The OR combinator check only works on the top most level of added where clauses. Additionally, if you do not add any where clauses inside your scope, nothing changes.
The breaking change part is if you were relying on these statements residing at the same level without grouping. If so, you will need to group your changes into a single scope where you control the grouping or do the querying at the builder level outside of scopes.
3.0.0
Adobe ColdFusion 11 and Lucee 4.5 are no longer supported
Please migrate to a supported engine.
Virtual Inheritance support removed
Virtual Inheritance allowed you to use a quick annotation on your entity instead of extending quick.models.BaseEntity. This was hardly used and didn't offer any benefit to extending using traditional inheritance. Additionally, removing the support allows us to clean up the code base by removing duplicate code paths.
If any of your entities are using the quick annotation, instead have them extends="quick.models.BaseEntity".
`accessors="true"` required for all entities
From the early days of Quick, developers have wanted to have accessors="true" on their entities. Because of this, Quick supported defining entities both with and without accessors. However, just as with virtual inheritance, it created two code paths that could hide bugs and make it hard to follow the code. In Quick 3.0.0, accessors="true" is required on all entities. If it is omitted, a helpful error message is thrown to remind you. This will help immensely in simplifying the code base. (In fact, just introducing this requirement helped find two bugs that were only present when using accessors.)
Ensure all entities have accessors="true" in their component metadata.
AssignedKey removed
Use NullKeyType instead.
Boolean casts updates to hook in to new Cast system
Previously, the only valid cast type was casts="boolean". In introducing the new Casts system, the boolean cast was refactored to use the same system. For this reason, any casts="boolean" needs to be changed to casts="BooleanCast@quick"
defaultGrammar updated to be the full WireBox mapping
In previous versions, the value passed to defaultGrammar was used to look up a mapping in the @qb namespace. This made it difficult to add or use grammars that weren't part of qb. (You could get around this be registering your custom grammar in the @qb namespace, but doing so seemed strange.)
To migrate this code, change your defaultGrammar to be the full WireBox mapping in your moduleSettings:
re-tooled to be based on relationships
It no longer accepts any entities or columns. Rather, it accepts an array of relationships to walk "through" to end up at the desired entity.
Here's how the old syntax would be used to define the relationship between Country and Post.
This same relationship now needs to be defined in terms of other relationships, like so.
This approach does require a relationship defined for each level, but it works up and down any number of relationships to get to your desired entity.
`` cannot be called on unloaded entities
To update the foreign key of a belongsTo relationship you use the associate method. In the past, it was possible to associate a new, unsaved child entity to its parent using this method.
In an attempt to provide more helpful error messages, this behavior is no longer possible. You can achieve the same effect in one of two ways.
The first is to manually assign the foreign keys:
While this works, it breaks the encapsulation provided by the relationship.
The second approach is to use the hasOne or hasMany side of the relationship to create the new child entity:
If you have all the data handy in a struct, you can use the create method for a more concise syntax.
This is the recommended way of creating these components.
assignAttributesData argument renamed to `attributes`
This brings the API in line with the other methods referencing attributes.
Method changes due to compound key support
Compound key support required some method and parameter name changes. Although the list seems extensive, you will likely not need to change anything in your code unless you have extended built-in Quick components. (You will see many relationship parameter name changes. Note that the function you call to define a relationship is a function on the BaseEntity and has not changed its signature.)
This component now extends quick.models.Relationships.HasOneOrManyThrough
init arguments are now as follows:
HasOneOrMany.cfc
init arguments have changed
foreignKey : String -> foreignKeys : [String]
PolymorphicBelongsTo.cfc
init arguments have changed
foreignKey : String -> foreignKeys : [String]
PolymorphicHasOneOrMany.cfc
init arguments have changed
id : String -> ids : [String]
2.0.0
Quick 2.0 brings with it a lot of changes to make things more flexible and more performant. This shouldn't take too long — maybe 2-5 minutes per entity.
Internal properties renamed
There were some common name clashes between internal Quick properties and custom attributes of your entities (the most common being fullName). All Quick internals have been obfuscated to avoid this situation. If you relied on these properties, please consult the following table below for the new property names.
If you are renaming your primary keys in your entities, you will have to change your key definition from variables.key = "user_id"; to variables._key= "user_id"; See for details.
Old Property Name
New Property Name
Additionally, some method names have also changed to avoid clashing with automatically generated getters and setters. Please consult the table below for method changes.
Old Method Name
New Method Name
Lastly, the following properties and methods have been removed:
Removed Property or Method
Key Types
Defining Key Types
Key Types are the way to define setting and retrieving a primary key in Quick. In Quick 1.0 these were injected in to the component. This made reusability hard for simple things like sequence names. In order to allow for more flexible key types, key types are no longer injected. Instead, they should be returned from a keyType method.
The keyType is lazily created and cached on the component, so this is both a more flexible approach as well as being more performant. If you are injecting custom key types in your entities you will need to move them to the method syntax.
Changed Key Types
A few key types have been renamed and will need to be updated in your codebase:
Old Key Type Name
New Key Type Name
New Key Types
In additional to the changes to defining key types, there is a few new key types introduced in Quick 2.0.
ReturningKeyType
Used with grammars that return their primary key in the query response when inserting to the database. An example of this is NEWSEQUENTIALID in Microsoft SQL Server.
Scopes
The way arguments are passed to scopes have been updated to allow for default arguments. query is still the first argument. Other arguments will be passed in order after that. The args struct is no longer passed.
Relationships
The relationship methods are still named the same but some of the arguments have been changed to fix bugs and support better eager loading performance. Please for more details.
Additionally, the alternative syntax for defining relationships on a relationships struct has been removed. It created an unnecessary code path that had it's own share of bugs. All relationships should be defined as methods on the entity.
Removing CFCollection
CFCollection was included in Quick 1.0 as both a way to lazily eager load a relationship and as a compatibility layer for older CF versions. The compatibility that CFCollection provides, however, comes with a performance cost. Additionally, the majority of users wanted to use plain arrays as the return format. For those reasons, arrays are now the default return format for collections. CFCollections can still be used by specifying a different return format in the module settings.
Converting to Null
Null is a tricky thing in CFML. The same goes for interacting with nulls in a database. By default, we will support the CFML convention of using an empty string to represent null. When interacting with the database empty strings will be converted to nulls. You can adjust this behavior on the property level with two new annotations:
convertToNull - Determines if the property will be automatically checked to convert to null at all. Defaults to true.
nullValue - This is the value that is equivalent to null for this property. Defaults to an empty string.
Returning Null instead of Unloaded Entities
In an effort to avoid dealing with CFML's version of null, Quick originally returned unloaded entities. You could check if an entity was loaded using the isLoaded method. This doesn't make as much sense as null however and even made it more difficult to interact with other libraries. Now Quick will return null when it encounters an empty query result either from a retrieval or from a belongsTo or hasOne relationship. Any instances that you were checking isLoaded should be updated. isLoaded will continue to exist for when you are creating a new entity not from the database.
AutoDiscover Grammar
The default grammar for Quick is now AutoDiscover. This provides a better first run experience. The grammar can still be set in the moduleSettings.
BaseService
As a new way to interact with Quick, you can use Quick Services to interact with your entities in a service-oriented fashion. These are equivalent to VirtualEntityServices in cborm.
The easiest way to use a Quick Service is to use the quickService: injection dsl.
All methods available on the Quick entity are available on the service.
Eager Loading
Eager loading is now supported for nested relationships using a dot-separated syntax. Additionally, constraints can be added to an eager loaded relationship. See the for more information.
Column Aliases in Queries
Column aliases can now be used in queries. They will be transformed to columns before executing the query.
Quick entities in Setters
If you pass a Quick entity to a setter method the entity's keyValue value will be passed.
Update and Insert Guards
Columns can be prevented from being inserted or updated using property attributes — insert="false" and update="false".
cbvalidation removed as a default dependency
Quick no longer automatically validates entities before saving them. Having cbvalidation baked in made it hard to extend it. If desired, validation can be added back in using Quick's lifecycle hooks.
instanceReady Lifecycle Method
Quick now announces an instanceReady event after the entity has gone through dependency injected and had its metadata inspected. This can be used to hook in other libraries, like cbvalidation and mementifier.
Automatic Attribute Casting
You can automatically cast a property to a boolean value while retrieving it from the database and back to a bit value when serializing to the database by setting casts="boolean" on the property.
/**
* Called to handle any tasks before inserting into the database.
* Receives the entity as the only argument.
*
* @entity The entity that is being inserted.
* @builder The builder that is doing the inserting.
*
* @return void
*/
public void function preInsert( required any entity, required any builder );
function scopeAddAuthorName( qb ) {
qb.addSubselect( "authorName", "author.name" );
}
function applyGlobalScopes() {
this.addVendorName();
this.addLocationName();
}
function applyGlobalScopes( qb ) {
qb.addVendorName();
qb.addLocationName();
}
Once you have an entity and its associated database table you can start retrieving data from your database.
You can configure your query to retrieve entities using any qb method. It is highly recommended you become familiar with the qb documentation.
Active Record
You start every interaction with Quick with an instance of an entity. The easiest way to do this is using WireBox. getInstance is available in all handlers by default. WireBox can easily be injected in to any other class you need using inject="wirebox".
Quick is backed by qb, a CFML Query Builder. With this in mind, think of retrieving records for your entities like interacting with qb. For example:
In addition to using for you can utilize the each function on arrays. For example:
You can add constraints to the query just the same as you would using qb directly:
For more information on what is possible with qb, check out the .
Quick Service
A second way to retrieve results is to use a Quick Service. It is similar to a VirtualEntityService from cborm.
The easiest way to create a Quick Service is to inject it using the quickService: dsl:
If you have a existing Service, and you would like to extend the quickService, you can extend the quikc.models.BaseService and then call super.init inside of the service init function passing the name of the entity (for example your User Entity) shown below:
Any method you can call on an entity can be called on the service. A new entity will be used for all calls to a Quick Service.
If you need a new unsaved entity from your service, you can call myService.newEntity()
Aggregates
Calling qb's aggregate methods (count, max, etc.) will return the appropriate value instead of an entity or collection of entities.
existsOrFail
Returns true if any entities exist with the configured query. If no entities exist, it throws an EntityNotFound exception.
Retrieval Methods
all
Retrieves all the records for an entity. Calling all will ignore any non-global constraints on the query.
get
Executes the configured query, eager loads any relations, and returns the entities in a new collection.
paginate
Executes the configured query, eager loads any relations, and returns the entities in the configured qb pagination struct.
simplePaginate
Executes the configured query, eager loads any relations, and returns the entities in the configured qb simple pagination struct.
first
Executes the configured query and returns the first entity found. If no entity is found, returns null.
firstWhere
Adds a basic where clause to the query and returns the first result.
firstOrFail
Executes the configured query and returns the first entity found. If no entity is found, then an EntityNotFound exception is thrown with the given or default error message.
firstOrNew
Finds the first matching record or returns an unloaded new entity.
firstOrCreate
Finds the first matching record or creates a new entity.
find
Returns the entity with the id value as the primary key. If no record is found, it returns null instead.
findOrFail
Returns the entity with the id value as the primary key. If no record is found, it throws an EntityNotFound exception.
findOrNew
Returns the entity with the id value as the primary key. If no record is found, it returns a new unloaded entity.
findOrCreate
Returns the entity with the id value as the primary key. If no record is found, it returns a newly created entity.
newEntity
You will probably not use newEntity very often if you use wirebox getinstance("someQuickEntity") to retrieve an entity, because that will already give you a new entity. If you are using a QuickService you will need this method for creating a new entity
Hydration Methods
Hydration is a term to describe filling an entity with a struct of data and then marking it as loaded, without doing any database queries. For example, this might be useful when hydrating a user from session data instead of doing a query every request.
hydrate
Hyrdates an entity from a struct of data. Hydrating an entity fills the entity and then marks it as loaded.
If the entity's keys are not included in the struct of data, a MissingHydrationKey is thrown.
hydrateAll
Hydrates a new collection of entities from an array of structs.
Custom Collections
If you would like collections of entities to be returned as something besides an array, you can override the newCollection method. It receives the array of entities. You can return any custom collection you desire.
newCollection
Returns a new collection of the given entities. It is expected to override this method in your entity if you need to specify a different collection to return. You can also call this method with no arguments to get an empty collection.
errorMessage
any
false
"No [#entityName()#] found with id [#arguments.id#]"
An optional string error message or callback to produce a string error message. If a callback is used, it is passed the unloaded entity as the only argument.
maxRows
numeric
false
25
The number of rows to return.
maxRows
numeric
false
25
The number of rows to return.
operator
any
true
The operator to use for the constraint (i.e. "=", "<", ">=", etc.). A value can be passed as the operator and the value left null as a shortcut for equals (e.g. where( "column", 1 ) == where( "column", "=", 1 ) ).
value
any
false
The value with which to constrain the column. An expression (builder.raw()) can be passed as well.
combinator
string
false
"and"
The boolean combinator for the clause (e.g. "and" or "or"). Default: "and"
newAttributes
struct
false
{}
A struct of attributes to fill on the new entity if no entity is found. These attributes are combined with attributes.
ignoreNonExistentAttributes
boolean
false
false
If true, does not throw an exception if an attribute does not exist. Instead, it skips the non-existent attribute.
newAttributes
struct
false
{}
A struct of attributes to fill on the created entity if no entity is found. These attributes are combined with attributes.
ignoreNonExistentAttributes
boolean
false
false
If true, does not throw an exception if an attribute does not exist. Instead, it skips the non-existent attribute.
errorMessage
any
false
"No [#entityName()#] found with id [#arguments.id#]"
An optional string error message or callback to produce a string error message. If a callback is used, it is passed the unloaded entity as the only argument.
attributes
struct
false
{}
A struct of attributes to fill on the new entity if no entity is found.
ignoreNonExistentAttributes
boolean
false
false
If true, does not throw an exception if an attribute does not exist. Instead, it skips the non-existent attribute.
attributes
struct
false
{}
A struct of attributes to use when creating the new entity if no entity is found.
ignoreNonExistentAttributes
boolean
false
false
If true, does not throw an exception if an attribute does not exist. Instead, it skips the non-existent attribute.
ignoreNonExistentAttributes
boolean
false
false
If true, does not throw an exception if an attribute does not exist. Instead, it skips the non-existent attribute.
ignoreNonExistentAttributes
boolean
false
false
If true, does not throw an exception if an attribute does not exist. Instead, it skips the non-existent attribute.
Name
Type
Required
Default
Description
id
any
false
Name
Type
Required
Default
Description
No arguments
``
Name
Type
Required
Default
Description
No arguments
``
Name
Type
Required
Default
Description
page
numeric
false
1
Name
Type
Required
Default
Description
page
numeric
false
1
Name
Type
Required
Default
Description
No arguments
``
Name
Type
Required
Default
Description
column
any
true
Name
Type
Required
Default
Description
errorMessage
any
false
"No [#entityName()#] found with constraints [#serializeJSON( retrieveQuery().getBindings() )#]"
The name of the column with which to constrain the query. A closure can be passed to begin a nested where statement.
An optional string error message or callback to produce a string error message. If a callback is used, it is passed the unloaded entity as the only argument.
A struct of attributes to restrict the query. If no entity is found the attributes are filled on the new entity returned.
A struct of attributes to restrict the query. If no entity is found the attributes are filled on the new entity created.
The id value to find.
The id value to find.
The id value to find.
The id value to find.
wirebox name of the quick entity
A struct of key / value pairs to fill in to the entity.
An array of structs to hydrate into entities.
The array of entities returned by the query.
var users = getInstance( "User" ).all();
for ( var user in users ) {
writeOutput( user.getUsername() );
}
var users = getInstance( "User" ).all();
prc.users.each( function( user ) {
writeOutput( user.getUsername() );
});
var user = getInstance( "User" )
//or
property name="UserService" inject="quickService:User"; //inject a quick service
var user = UserService.newEntity();